本文共 1653 字,大约阅读时间需要 5 分钟。
curl -o /dev/null -s -w %{time_total}"\n" www.yy.com
-w %{option} //指定要获取的指标
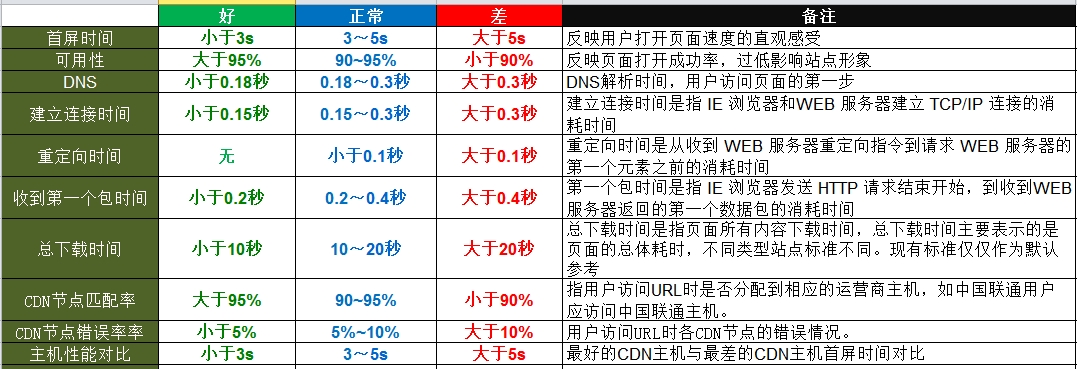
可获取的指标,如下所示:
time_total //完成请求所用的时间
time_namelookup //解析完成的时间
time_connect //建立到服务器的 TCP 连接所用的时间
time_pretransfer //链接建立完成准备响应时间
time_redirect //重定向完成时间
time_starttransfer //在发出请求之后,Web 服务器返回数据的第一个字节所用的时间
http_code //http返回类似404,200,500等
size_download //下载网页或文件大小
size_upload //上传文件大小
size_header //响应头
size_request //发送请求参数大小
speed_download //传输速度
speed_upload //平均上传速度
content_type //下载文件类型. (Added in 7.9.5)
由于网站可能做了keepalive,或者DNS缓存等等,通过curl一次性获取多组数据实际上有可能数据并不那么准确,较好的办法是每间隔一段时间去取一次值,一段时间之后再运行脚本获取平均值。定时获取执行curl命令需要借助crontab的帮助
#每分钟获取一次数据
root@node1:~# crontab –e
* * * * * curl –o /dev/null –s –w %{time_connect} www.yy.com >> /tmp/data/data_collected
#!/bin/bash
outputfile="/tmp/data/data_collected"
awk 'BEGIN{tt=0;tc=0;tr=0;tn=0;tp=0;ts=0}{tt+=$1;tc+=$2;tr+=$3;tn+=$4;tp+=$5;ts+=$6}\
END{print \
" time_total = "tt/NR"\n",\
"time_connect = "tc/NR"\n",\
"time_redirect = "tr/NR"\n",\
"time_namelookup = "tn/NR"\n",\
"time_pretransfer = "tp/NR"\n",\
"time_starttransfer = "ts/NR"\n"}' $outputfile
cat /dev/null > $outputfile
or 参考 http://jaseywang.me/
cat curl-format
time_namelookup: %{time_namelookup}\n
time_connect: %{time_connect}\n
time_appconnect: %{time_appconnect}\n
time_pretransfer: %{time_pretransfer}\n
time_redirect: %{time_redirect}\n
time_starttransfer: %{time_starttransfer}\n
———-\n
time_total: %{time_total}\n
curl -w "@curl-format.txt" -o /dev/null -s www.yy.com
为什么需要这个东西,因为有时候网站故障,就是dns解析慢等原因,前提是你需要学会抓包。
更好的是把这个东西加入zabbix
参考http://xiaoluoge.blog.51cto.com/9141967/1829233
本文转自 liqius 51CTO博客,原文链接:http://blog.51cto.com/szgb17/1854826,如需转载请自行联系原作者